대규모 클러스터를 모니터링 하는 과정에서 간혹 ssh 접속이 안되는 문제가 발생한다. 모니터링을 수행하는 서버에서 주기적으로 클러스터의 각 노드에 접속해서 동작하고 있어야하는 데몬들이 정상적으로 떠있는지를 확인하게 되는데, 이 과정에서 ssh 접속이 안되는 문제가 발생했다. sshd 등의 데몬은 정상 동작하고 있었다.
특이한 점은 특정 호스트에서만 접속 오류가 보고되는게 아닌 클러스터의 노드들이 랜덤하게 'ssh connectin timed out' 메시지를 보인다는 것이었다. 문제를 확인하기 위해 직접 문제의 서버로 ssh 접속을 하면 접속이 잘 된다. 하이젠버그를 몸소 체함하면서 문제의 원인을 분석해봤다.
1. nf_conntrack: table full dropping packet 메시지
ssh 접속 문제가 발생했던 호스트에는 별다른 문제가 없었다. 모니터링 서버에서 ssh 접속 실패로그를 찍은 모든 호스트에 접속해서 커널 로그들을 열어봤지만 큰 문제점을 발견하지는 못했다.
모니터링 서버의 모니터링 스크립트도 분석해봤지만 문제는 없었다. 모니터링 서버의 커널 로그를 열어보니 문제점을 볼 수 있었다. dmesg를 이용해 모니터링 서버의 커널로그를 확인해보니 다음과 같은 메시지들이 남아있었다.
[2538157.054528] nf_conntrack: table full, dropping packet.
[2538157.166357] nf_conntrack: table full, dropping packet.
[2538157.263534] nf_conntrack: table full, dropping packet.
[2538157.366837] nf_conntrack: table full, dropping packet.
[2538157.467305] nf_conntrack: table full, dropping packet.
[2538157.569270] nf_conntrack: table full, dropping packet.
[2538157.663836] nf_conntrack: table full, dropping packet.
[2538157.765348] nf_conntrack: table full, dropping packet.
[2538157.867338] nf_conntrack: table full, dropping packet.
[2538157.963828] nf_conntrack: table full, dropping packet.
[2538157.9639928] nf_conntrack: table full, dropping packet
[2538157.989528] nf_conntrack: table full, dropping packet
[2538162.214064] __ratelimit: 61 callbacks suppressed'nf_conntrack: table full, dropping packet'이 계속 남아있었다. 마지막 메시지인 패킷을 드랍했다는 것이 ssh 접속 장애의 문제로 보였다. nf_conntrack이라는 커널 모듈에서 관리하는 어떤 테이블이 꽉차서 패킷을 처리할 수 없어쏙, 결국 처리하지 못한 패킷을 드랍했다는 의미로 해석되었다.
뭔가 nf_conntrack 모듈과 관련된 limit 값을 조정하면 문제가 해결될 것 같았다.
2. nf_conntrack
우선 nf_conntrack 모듈이 뭔지 찾아봤다. nf_conntrack은 ip_conntrack의 후속 커널 모듈이다. netfilter라고 하는 커널 프레임워크가 네트워크 연결에 대한 내용을 기록하고 추적하기 위해 사용하는 모듈이라고 한다. 리눅스 커널 2.6 버전에서 정식으로 추가되었다고 한다.
nf_conntrack 모듈은 일반적으로 비활성화되있지만 다음의 경우 활성화 된다.
-
docker 같은 iptables의 NAT 기능이 필요한 어플리케이션을 사용 할 경우
-
iptables -t nat -L 등의 NAT 테이블 확인 명령을 한번이라도 수행한 경우
네트워크 연결에 대한 내용을 트래킹(Tracking)하는 모듈로 평소에는 문제를 발생시키지 않지만 가끔 커넥션이 많은 서버에서 문제가 발생하는 경우가 있다고 한다.
2.1 nf_conntrack table
문제의 nf_conntrack 모듈은 네트워크 연결 정보를 해시 테이블로 기록한다.
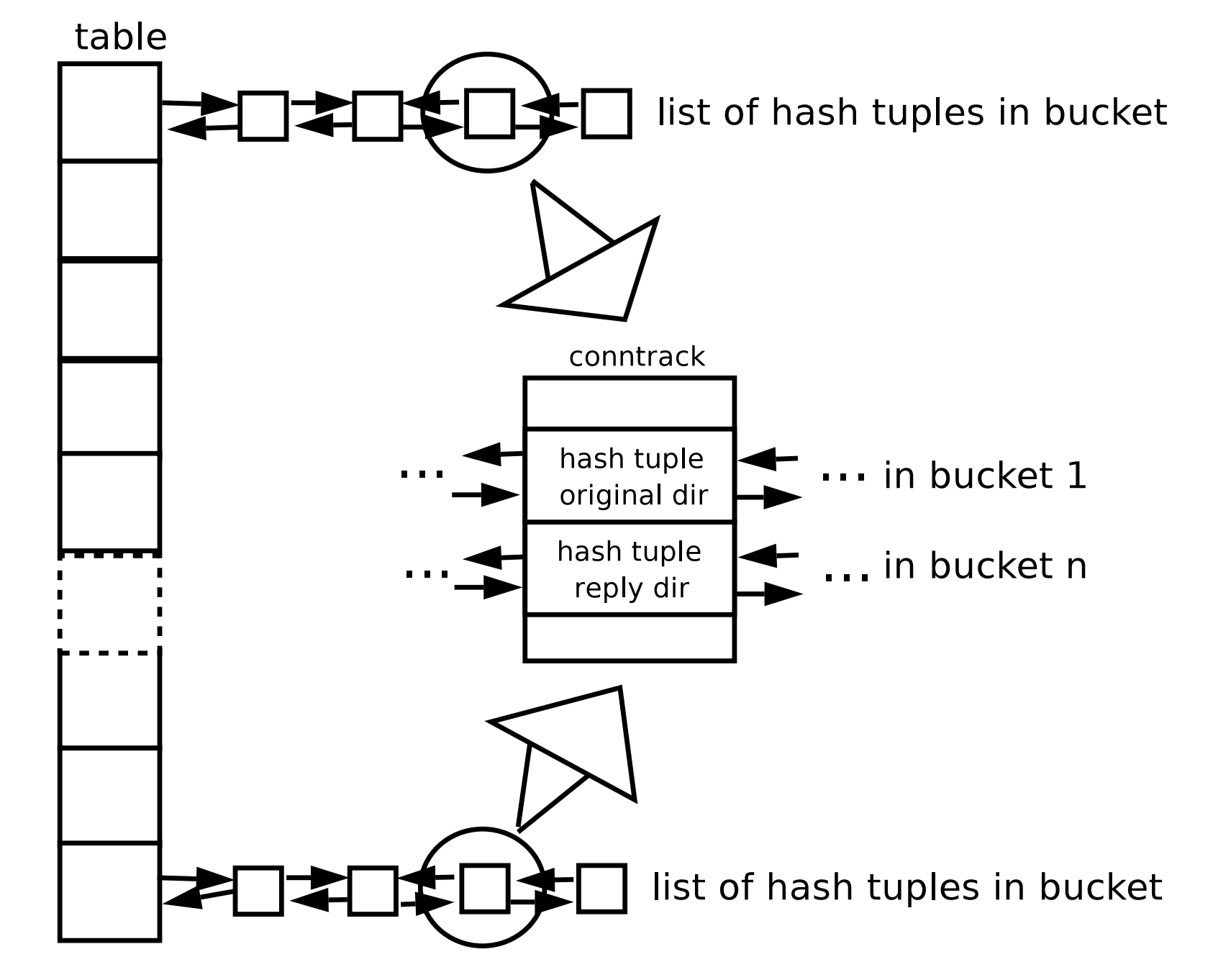
해시 테이블의 해시 버킷에 커넥션 트래킹 정보를 기록하는 노드가 이중 연결리스트로 연결되어 있는 형태다. nf_conntrack 모듈 구조는 위 그림과 같다. nf_conntrack 모듈이 이런 해시테이블 구조를 유지하는데 영향을 주는 파라미터로는 해시테이블의 버킷 개수를 지정하는 'nf_conntrack_buckets'와 해시테이블에 저장되는 노드의 최대 개수를 지정하는 'nf_conntrack_max'가 있다.
'nf_conntrack_buckets' 파라미터는 기본값이 16384이고, 'nf_conntrack_max'는 65536이다. "nf_conntrack: table full, dropping packet." 에러 메시지는 'nf_conntrack_max' 값을 넘어선 개수의 네트워크 세션이 열렸기 때문에 발생한 것이다. 이 문제를 해결하기 위해서는 'nf_conntrack_max' 값을 손보면 된다. (nf_conntrack과 관련된 다른 파라미터들은 https://www.kernel.org/doc/Documentation/networking/nf_conntrack-sysctl.txt 페이지를 확인해보자.)
2.2 nf_conntrack_max & nf_conntrack_buckets
해시 테이블과 관련된 파라미터를 조정할 때 성능 이슈가 발생한다.
"nf_conntrack: table full, dropping packet." 에러를 해결하기 위해 단순히 'nf_conntrack_max' 파라미터 값을 증가시키면 된다. 하지만 해시 테이블의 버킷 개수를 늘리지 않으면 해시 충돌(Collision)이 빈번하게 발생하고, 이중 연결리스트가 길어지면서 원하지 않는 성능 저하가 유발될 수 있다.
해시 테이블의 경우 해시버킷의 개수가 충분하면 O(1) 시간 복잡도로 노드를 찾아갈 수 있다. 하지만 그 값이 작아지면 해시 충돌(Hash Collision)이 발생하면서 O(N/h)의 시간 복잡도로 효율이 떨어진다. (이 때, N은 해시 테이블에 등록된 노드의 개수이며, h는 해시 버킷의 개수를 의미한다.)
nf_conntrack 모듈의 경우에도 해시 버킷의 개수를 조정하지 않은 채 노드의 최대 개수만 늘리면 해시 충돌 발생으로 nf_conntrack 모듈에서 네트워크 성능 저하가 발생할 수 있다. . 따라서 nf_conntrack_max 값과 함께 nf_conntrack_buckets 값도 같이 조정해주는게 좋다. (물론 경우에 따라서 성능 저하가 큰 문제가 아닌 경우 nf_contrack_max 값만 올려도 되긴한다.)
해시 버킷의 개수를 늘리는데 걸림돌이 되는 것 중 하나는 메모리 사용량이다. 해시 테이블의 버킷 헤더에 정보가 많다면 해시 테이블의 버킷 개수를 늘리는게 평소 메모리 사용량을 올려 부담스러워 질 수도 있다. 커널 소스를 잠깐 여러보자. (nf_conntrack_core.c 파일 참조)
void *nf_ct_alloc_hashtable(unsigned int *sizep, int nulls)
{
struct hlist_nulls_head *hash;
unsigned int nr_slots, i;
if (*sizep > (UINT_MAX / sizeof(struct hlist_nulls_head)))
return NULL;
BUILD_BUG_ON(sizeof(struct hlist_nulls_head) != sizeof(struct hlist_head));
nr_slots = *sizep = roundup(*sizep, PAGE_SIZE / sizeof(struct hlist_nulls_head));
hash = kvmalloc_array(nr_slots, sizeof(struct hlist_nulls_head), GFP_KERNEL | __GFP_ZERO);
if (hash && nulls)
for (i = 0; i < nr_slots; i++)
INIT_HLIST_NULLS_HEAD(&hash[i], i);
return hash;
}해시 테이블을 할당하는 함수다. 여기에서 해시 테이블은 다음 구조체(해시 버킷)의 배열이다.
struct hlist_nulls_head {
struct hlist_nulls_node *first;
};해시 버킷은 포인터 하나를 들고 있다. 64비트 아키텍처의 경우 해시버킷 하나당 8바이트를 소모한다. 'nf_conntrack_buckets'의 기본 값인 16384개의 해시 버킷을 유지하기위해 128kb의 메모리를 사용한다. 이를 64만개로 늘리면 약 5MB 정도의 메모리를 해시 버킷을 만드는데 사용하게 된다.
nf_conntrack 모듈은 304바이트 구조체를 이용해 해시 테이블에 커넥션 정보를 기록한다. (웹 문서를 참고했다. 실제 구조체 사이즈는 커널 내부에서 사용하는 SLAB Allocator에서 할당 받은 SLAB의 내부 단편화와 페이지 사이즈, 커널 버전 등에 따라 다를 수 있다.)
네트워크 세션 하나당 304 바이트의 메모리를 사용한다고 하면, 'nf_conntrack_max'의 기본 값인 65536개의 세션 정보를 저장하기 위해서 총 19MB의 메모리를 사용하게 된다. 패킷 드랍 문제를 해결하기 위해 nf_conntrack_max 값을 100만까지 늘린다고 생각해보자. 그러면 최대 289.92MB 가량의 메모리를 커넥션 정보를 기록하는데 사용하게 된다.
원하는 커넥션 개수에 따라 메모리 사용량을 계산해보고, 부담스럽지 않은 선으로 올리면 된다. 만약 운영에 문제가 있다면 커넥션을 여러 서버로 분산시키는 등의 다른 방법들을 찾아봐야 한다.
3. nf_conntrack 모듈 값 확인
그렇다면 현재 접속중인 서버의 nf_conntrack 모듈의 상태를 확인해보자.
3.1 nf_conntrack 모듈 확인
우선 nf_conntrack 모듈이 활성화되어 있는지 확인해보는 명령어는 다음과 같다.
cat /proc/modules | grep nf_conntrack/proc/modules 파일을 조회해보면 현재 활성화된 리눅스 모듈들의 정보를 확인할 수 있는데, 그 중에서 nf_conntrack과 과련된 내용을 찾아보면 된다.
3.2 nf_conntrack_max 값 확인
nf_conntrack 모듈이 활성화되어 있다면 nf_conntrack_max 값을 확인해보자.
cat /proc/sys/net/nf_conntrack_max
nf_conntrack_buckets 값도 확인해보자.
cat /proc/sys/net/netfilter/nf_conntrack_bucketsnf_conntrack_buckets의 기본 값은 32 ~ 16384 사이 숫자가 할당된다.
3.3 nf_conntrack_count - 현재 트래킹 중인 노드의 개수
그렇다면 현재 nf_conntrack 모듈이 트래킹하고 있는 네트워크 커넥션의 개수를 확인해보자.
cat /proc/sys/net/netfilter/nf_conntrack_count문제가 발생했다면 이 값이 순간적으로 치고 올라가면서 nf_conntrack_max 값을 넘게 되고, 커널 로그에 packet drop 메시지가 찍힐 것이다.
watch 명령으로 지속적인 모니터링도 가능하다.
watch -d cat /proc/sys/net/netfilter/nf_conntrack_count4. 해결방안
4.1 nf_conntrack 모듈 언로드
nf_conntrack 모듈을 써야하는 상황이 아니라면 모듈 자체를 언로드해버리는게 가장 깔끔한 해결책이다. nf_conntrack 모듈을 언로드해보자.
우선 iptables를 멈춘다.
iptables stop그리고 iptable rule 중에 state 구문이 들어가는 rule을 삭제한다.
그런 다음 다음 명령을 실행해서 nf_conntrack 모듈을 제거한다.
rmmod nf_conntrack4.2 nf_conntrack_max, nf_conntrack_buckets 파라미터 조정
모듈을 언로드해도 되는지 확실하지 않은 경우 혹은 관련되어 있는 모듈이 너무 많은 경우에는 위에서 설명했던 nf_conntrack_max와 nf_conntrack_buckets 파라미터를 조정해서 문제를 해결해야한다.
우선 다음 파일을 생성한다.
/etc/modprobe.d/nf_conntrack.conf그리고 다음 옵션을 추가한다.
options nf_conntrack hashsize={newValue}newValue에 수정할 값을 변경하면 된다.
여기서는 해시 테이블의 사이즈(버킷의 개수)를 조정하여 nf_conntrack_max 값을 조정하도록 한다. nf_conntrack_max 값은 별도로 지정하지 않으면 nf_conntrack_max 값의 8배로 지정된다. nf_conntrack_buckets 값을 늘려 nf_conntrack_max 값을 증가시키는 방법이 해시 Collision으로 인한 모듈 성능 저하를 피할 수 있기 때문에 권장되는 방식이라고 한다.
새로운 값을 지정했으면 netfilter를 사용하는 iptables 같은 모듈을 재시작한다.
우분투의 경우 ufw를 재시작한다. (Ubuntu FireWall)
$ systemctl stop ufw
$ modprobe -rv nf_conntrack
$ systemctl start ufwCentOS의 경우 다음 명령을 실행한다.
$ systemctl stop iptables
$ modprobe -rv nf_conntrack
$ systemctl start iptables만약 modprob 명령에서 modprobe: FATAL: Module nf_Conntrack is in use 에러가 발생한다면, nf_conntract 모듈을 사용하는 다른 모듈이 있는지 확인한 다음 언로드하고 진행하면 된다.
4.3 적당한 값은?
nf_conntrack_max 값을 구하는 공식은 웹 페이지에서 어렵지 않게 찾아 볼 수 있다. 과거 ip_conntrack 모듈 시절에 계산법이 있는데 다음과 같다.
nf_conntrack_max = (MemorySize) / (16384 * (architecture bit / 32 ))
nf_conntrack_buckets = nf_conntrack_max / 8적당한 값에 대한 근사치일 뿐, 실제 서버의 운영 환경에 따라 다양한 값으로 설정해 사용해도 무방하다. 특히 메모리를 많이 쓰는 서버인지, 커맨드 서버인지 등에 따라 적당한 값을 조정해가면서 사용해야한다.
Reference
-
Netfilter's connection tracking system - http://people.netfilter.org/pablo/docs/login.pdf
-
nf_conntract_* Kernel documents - https://www.kernel.org/doc/Documentation/networking/nf_conntrack-sysctl.txt
-
Tuning your Linux kernel and HAProxy instance for high loads - https://medium.com/@pawilon/tuning-your-linux-kernel-and-haproxy-instance-for-high-loads-1a2105ea553e
-
소스코드 확인 - https://elixir.bootlin.com/linux/latest/source/include/net/netfilter/nf_conntrack.h#L58



댓글