하둡 스트리밍(Hadoop Streaming)은 하둡과 함께 배포되는 유틸리티다. 하둡에서 MapReduce(이하 MR) 작업을 실행하기 위해서는 기본적으로 자바 언어를 이용해야 한다. 하지만 하둡은 하둡 스트리밍을 통해서 자바 이외에 파이썬이나 루비, Bash 스크립트 등으로도 MR 작업을 생성하고 실행할 수 있게 해준다.
하둡 스트리밍 동작 방식
하둡 스트리밍은 유닉스 스트림을 이용해 자바가 아닌 프로그램 혹은 스크립트가 MR 작업으로 동작하도록 해준다. 즉, 표준입력(stdin)과 표준출력(stdout)을 통해 입출력을 하는 프로그램과 스크립트는 하둡 스트리밍을 통해 MR의 Mapper 혹은 Reducer로 사용할 수 있다.
하둡 스트리밍은 다음과 같이 동작한다.
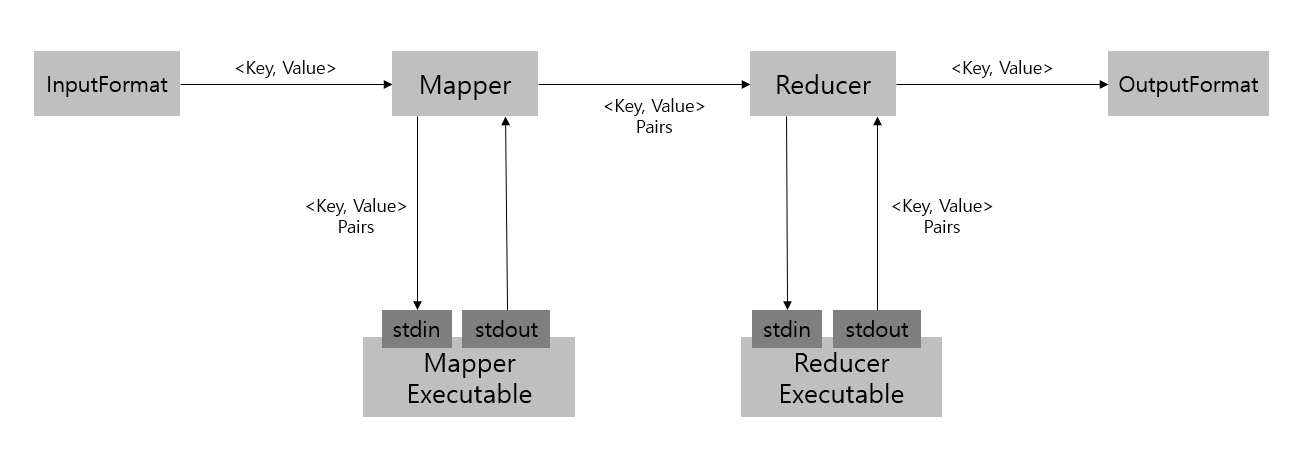
하둡 스트리밍 유틸리티는 Mapper와 Reducer로 지정된 프로그램을 이용해 MR 작업을 생성한 후 하둡 클러스터로 Submit 한다. 그리고 Submit 된 작업의 실행을 모니터링한다.
Submit 된 MR 작업이 초기화 되는 과정에서 Mapper들이 초기화(Initialize)될 때, 별도 프로세스를 생성해서 Mapper로 사용될 프로그램이나 스크립트를 실행하게 된다. 이 후, Mapper는 InputFormat에서 만들어진 Key-Value 쌍을 Mapper로 사용될 프로그램의 표준 입력으로 텍스트 라인 형태로 넘겨준다. 기본적으로 Key에 해당하는 문자열과 Value에 해당하는 문자열을 탭 문자(\t)로 붙여서 텍스트로 만든다. (탭 문자 대신 다른 문자를 사용하도록 설정할 수 있다.)
Mapper로 사용될 프로그램은 표준입력으로 받은 Key-Value를 처리하고 표준 출력으로 텍스트를 출력한다. 그러면 Mapper는 이를 Key-Value 쌍으로 다시 변환해서 정렬하고 그루핑해서 Reducer로 넘겨준다.
Reducer의 경우도 비슷하게 초기화 단계에서 별도의 프로세스가 실행되어 Reducer 프로그램을 실행한다. Reducer 역시 Key-Value 쌍을 텍스트 라인 형태로 만들어서 표준입력으로 넣어주고, 표준출력에서 나오는 Key-Value 텍스트를 받아서 OutputFormat으로 넘겨준다.
MR 프레임워크와 Mapper 혹은 Reducer로 사용될 프로그램 사이에서는 Key와 Value를 탭(\t) 문자로 붙여서 전달하고 전달 받는다. 만약 탭 문자가 텍스트 라인에 없다면 라인 전체가 Key이고 Value는 null인 것으로 간주된다.
하둡 스트리밍 실행
하둡 스트리밍은 다음과 같이 실행할 수 있다.
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input inputDirs \
-output outputDir \
-mapper /bin/cat \
-reducer /usr/bin/wc-mapper 옵션과 -reducer 옵션으로 준 실행파일이 MR의 Mapper와 Reducer로 사용된다. -input 옵션과 -output 옵션은 각각 Mapper의 입력 경로와 Reducer의 출력 경로에 해당한다.
옵션
하둡 스트리밍은 여러 옵션들을 지원한다.
| 옵션 | 설명 |
| -input | Mapper의 입력 파일들이 있는 위치 (필수 입력) |
| -output | Reducer의 출력 파일들이 저장될 위치(필수 입력) |
| -mapper | Mapper로 사용할 스크립트나 실행 파일, 입력하지 않으면 IdentityMapper를 사용 |
| -reducer | Reducer로 사용할 스크립트나 실행 파일, 입력하지 않으면 IdentityReducer를 사용 |
| -inputformat | MR 작업에서 InputFormat으로 사용될 클래스. Text.class의 Key-Value 쌍을 리턴해야함. 기본값은 TextInputFormat |
| -outputformat | MR 작업에서 OutputFormat으로 사용될 클래스. Text.class의 Key-Value 쌍을 입력으로 받아야 함. 기본값은 TextOutputFormat |
| -numReduceTasks | 리듀서의 개수 |
| -file | Mapper, Reducer, Combiner로 사용될 실행파일이나 스크립트를 입력하면 하둡 클러스터의 컴퓨트 노드에 복사되어 MR 작업이 실행됨 |
| -mapebug | Map 태스크가 실패했을 때 실행될 스크립트 |
| -reducedebug | Reducer 태스크가 실패했을 때 실행될 스크립트 |
| -partitioner | Mapper에서 나온 Key-Value 쌍에 대해 어떤 키를 어떤 Reducer로 보낼지 결정하는데 사용되는 클래스 |
하둡스트리밍 예제
파이썬으로 작성된 프로그램을 하둡 스트리밍에서 실행하는 예제를 살펴보자. MR 예제 중 가장 간단한 예제인 WordCount 프로그램을 만들어보자.
일단 단어 개수를 셀 파일을 만들어 준다. 위키 백과에서 랜덤 아티클을 가져왔다. 로컬에서 input 파일에 아티클을 저장한 다음 MR에서 읽을 수 있게 HDFS에 올려준다.
$ hdfs dfs -mkdir /user/accout/input
$ hdfs dfs -put input /user/accout/input
$ hdfs dfs -ls /user/accout/input
-rw-r--r-- 3 account 2019 2022-08-01 22:01 /user/account/input/inputWordCount에서 실행할 Mapper를 작성한다. 텍스트 파일의 라인을 입력으로 받아서 공백으로 자른다음 탭 문자를 기준으로 Key, Value를 출력해준다. 이 때, Key는 단어이고 Value는 숫자 1을 쓰면 된다.
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words= line.split()
for word in words:
value = 1
print("%s\\t%d" % (word , value))이제 Reducer를 작성하자. Reducer로 넘어올 때, Key, Value는 정렬과 그루핑이 된 상태이므로 간단하게 WordCount를 할 수 있다.
#!/usr/bin/env python
import sys
last_word = None
total_count = 0
for line in sys.stdin:
line = line.strip()
word, value = line.split("\\t", 1)
value = int(value)
if last_word == word:
total_count += value
else:
if last_word:
print("{0}\\t{1}".format(last_word , total_count ))
total_count = value
last_word = word
if last_word == word:
print("{0}\\t{1}".format(last_word , total_count ))작성한 Mapper와 Reducer의 퍼미션을 변경해준다.
$ chmod +x mapper.py
$ chmod +x reducer.py이제 하둡 스트리밍을 활용해 mapper.py와 reducer.py를 실행해준다.
$ hadoop jar /usr/lib/hadoop-streaming.jar \
-input /user/account/input \
-output /user/account/output \
-mapper /home/account/mapper.py \
-reducer /home/account/reducer.pyMR 실행이 완료되면 output으로 입력한 HDFS 경로에 결과물이 생성되어 있는 것을 볼 수 있다.
$ hdfs dfs -ls /user/account/output
Found 2 items
-rw-r--r-- 3 account account 0 2022-08-01 22:10 /user/account/output/_SUCCESS
-rw-r--r-- 3 account account 974 2022-08-01 22:10 /user/account/output/part-00000.gzpart-00000.gz 파일을 다운로드해서 압축을 풀어보면
"cowboy 1
1800s. 1
1946. 1
19th 1
322,000 1
American, 1
Among 1
Another 1
Basin 1
Basque 2
Boise 1
Boise. 1
British, 1
C. 1
Camp 1
Cente 1
Center[6] 1
Clark 1
Clearwater 1
Cultural 2
European-Americans 1
Expedition 1
...알파벳 순으로 정렬되어 있는 단어들과 숫자들을 확인해 볼 수 있다.




댓글